
自上学期学完《网络渗透测试技术》以来的第一次实战,终于过了一把网安的瘾
Note: 此次隐患已联系相关老师(处理)
背景
L 校图书馆因毕业季到来,希望给同学们留下一个美好的回忆,让同学们看看大学这几年究竟进了多少次图书馆,借了几本书(咳咳咳,某些同学啊,他喜欢去教室自习,喜欢看电子书),所以弄了这样一个服务。应该说想法是相当不错的,很有人文关怀。
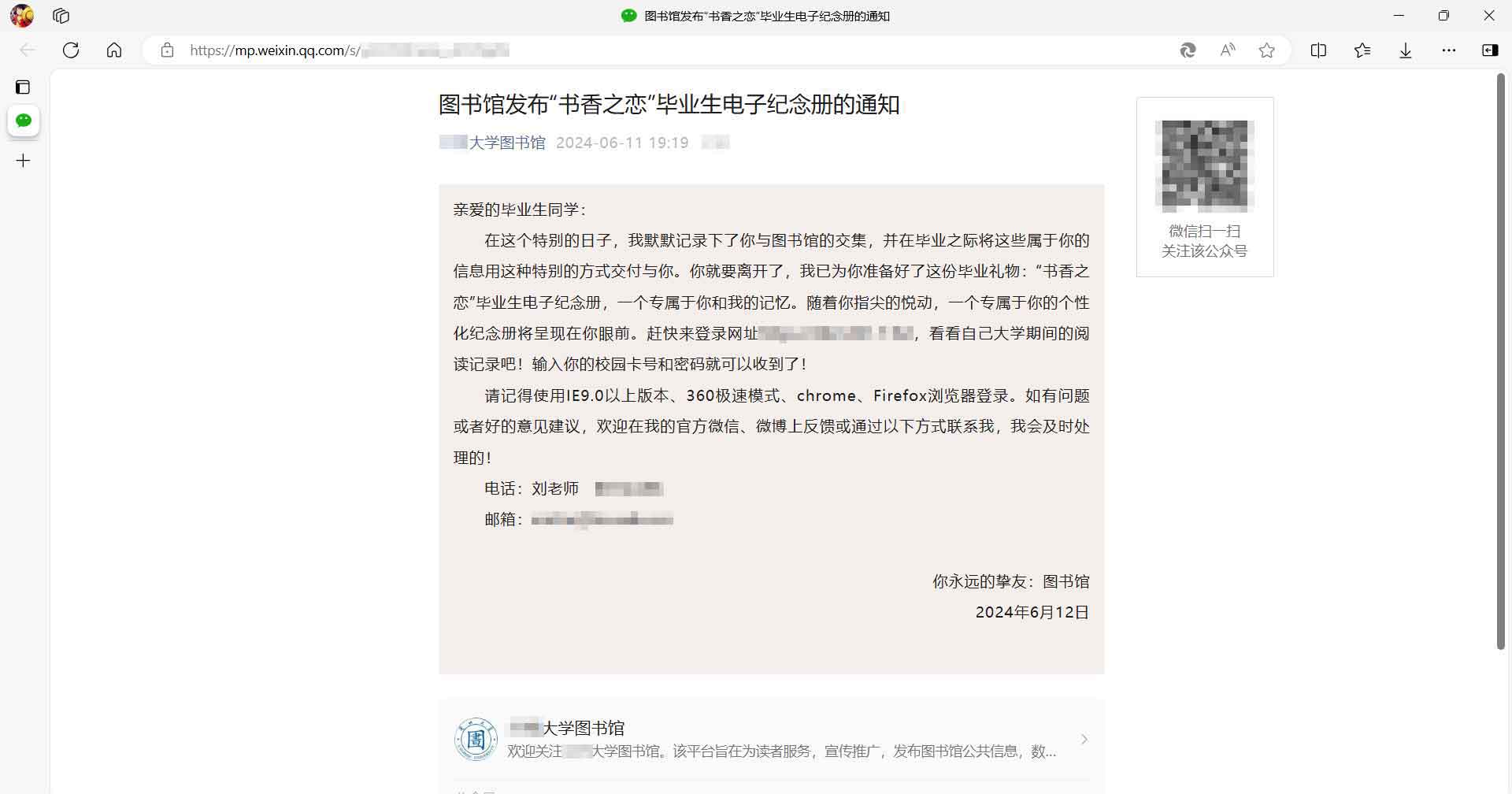
但是这个简陋的网页加上这个随意的网址不能不引起我人们的注意,而且登录只需要账号!所以,当天我就在班级群里翻出了本班同学的校园卡号,然后在某节无聊的课上逐一手动登录之。不得不说,那真是太好玩了!能看到成绩很好的同学居然去图书馆的次数一般,而且借书不多;还有xxx居然看hhh!
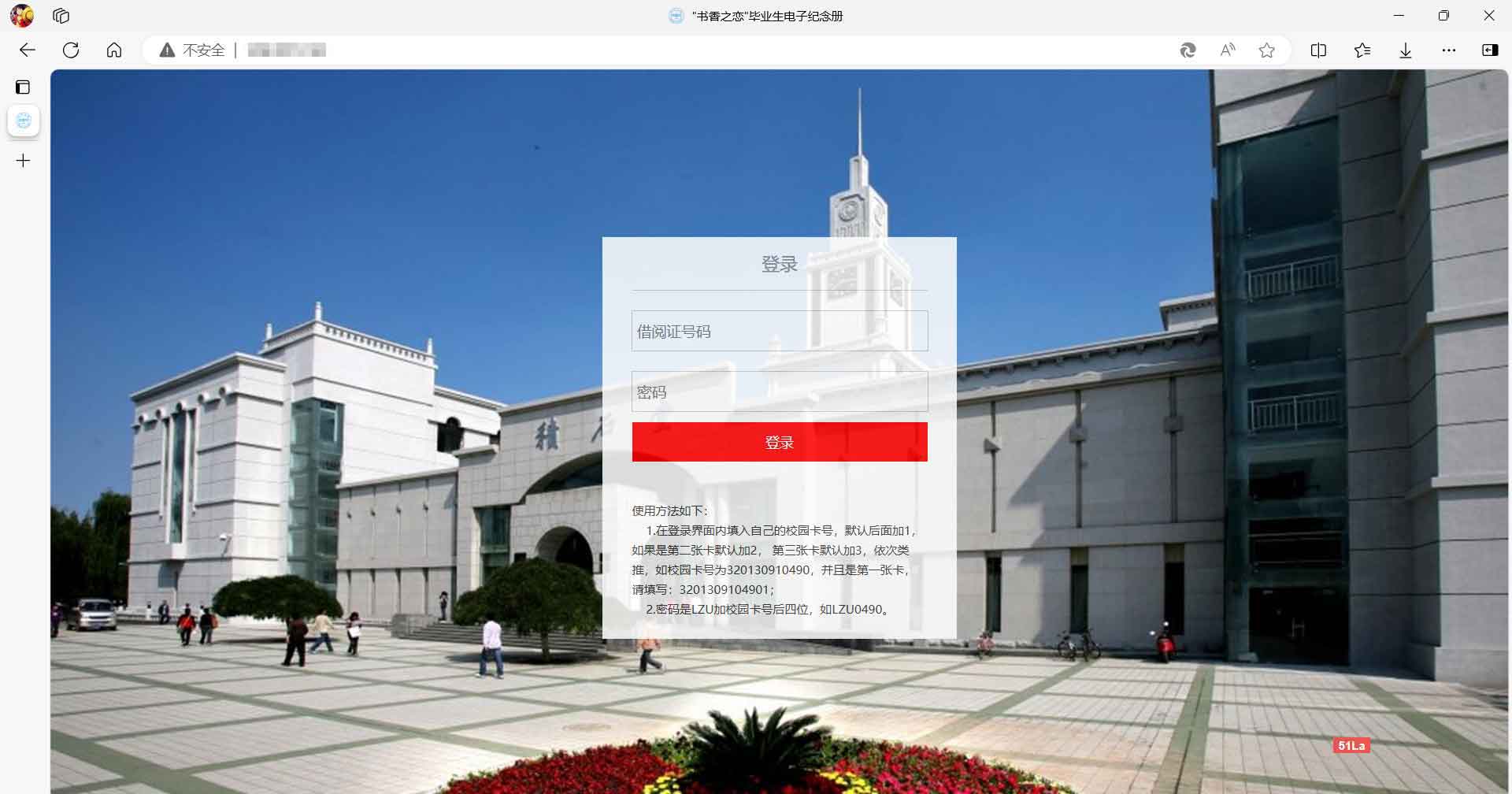
可是这样一个一个试很慢也很麻烦,所以当晚我就用Python写了一个脚本,找到之前有本院同学校园卡号的文件,先爬了本院的(那天熬到很晚,影响了室友休息,非常抱歉!)。第二天,为了将功补过,也为了测试程序,我找jzy室友要来了他们院的校园卡号爬了一遍,然后我们就凑在一块分析,又想着能不能把整个年级的爬下来,再后来就想到了扫描 ……
扫描
一开始我是不赞成这个方法的,一方面容易被发现,这是最大的担忧,只要在服务器上开一个监听程序,通过IP一查就知道是谁做的了;另一方面校园卡号12位 + 序列号1位,总共13位,遍历爬取效率太低也不现实,况且不知道什么时候图书馆会关闭这个服务。在爬完手头上已有的校园卡号后,发现服务还没有关闭,也没有网安追查过来。于是,究竟抵不过好奇和无聊,开始尝试扫描。
扫描的第一要务是弄清校园卡号的设置规律。利用手头已有的本院校园卡号,先依照校园卡号大小顺序进行排序,从上往下翻的过程中就会发现前面几个数字都是相同的 32021094xxxx 只是最后四位不清楚。意义也比较的明了, 3 是本科生, 202109 是入学年月。而我又记起一位学长和我说过最后一位只有 0 和 1 两种,表示性别,对照着看了一下确实如此。后来又和jzy比对了他们院的校园卡号,发现入学年月后面的 4 不是必须的,他们院就为 0 。因而入学年月后面的四位也能猜个大概,大致只能是序号了。最后得到校园卡号的编码规则如下:

确定规则后,就写了一个程序试着爬了一下2021级本科生。序号遍历范围为 0~4999 ,最后一位在 0 或 1 之间取值,结果爬了有4800多条数据,而 L 校一个年级的本科生大致在5000人左右,印证了前面关于校园卡号编码规则的推断。
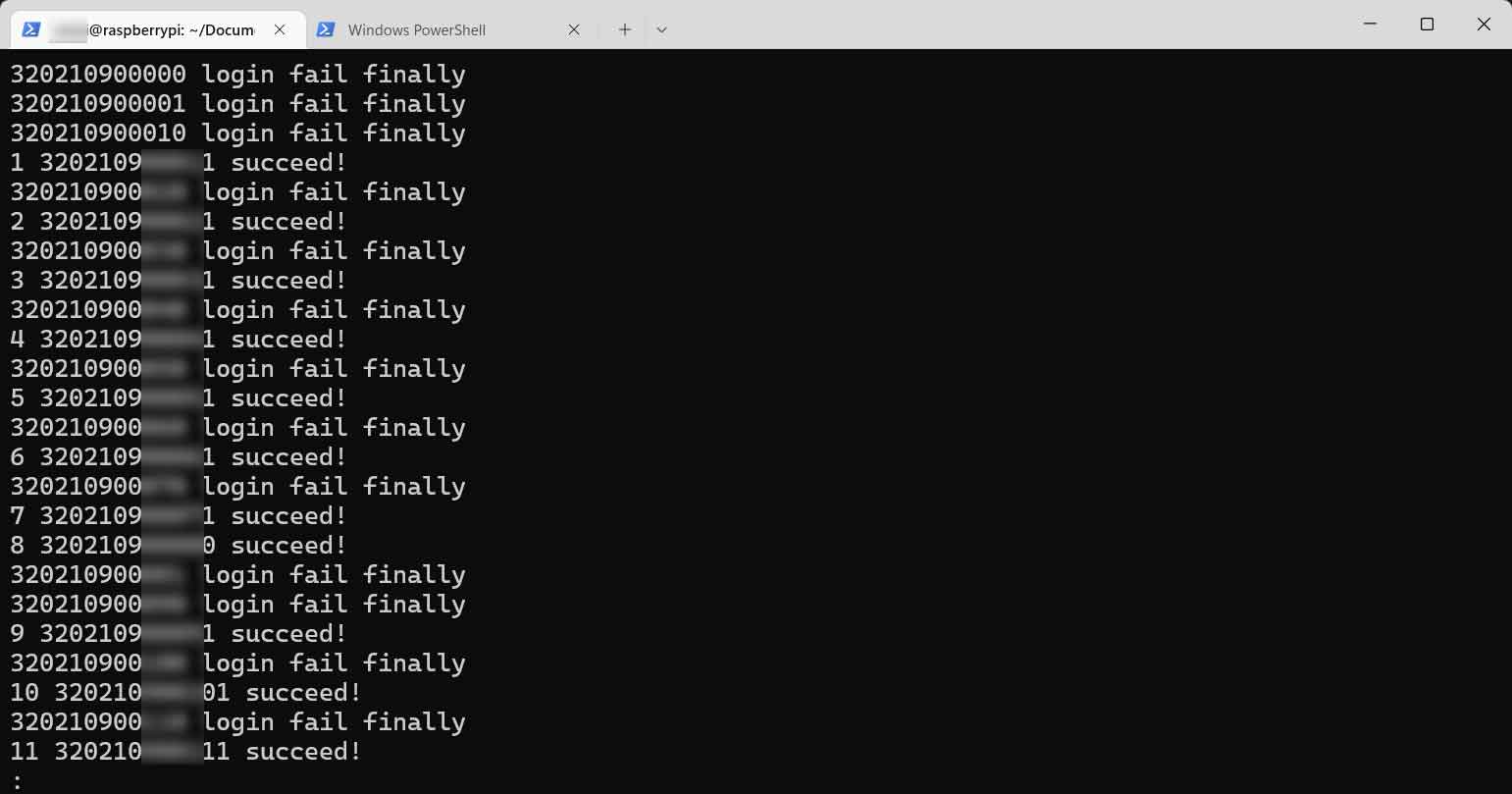
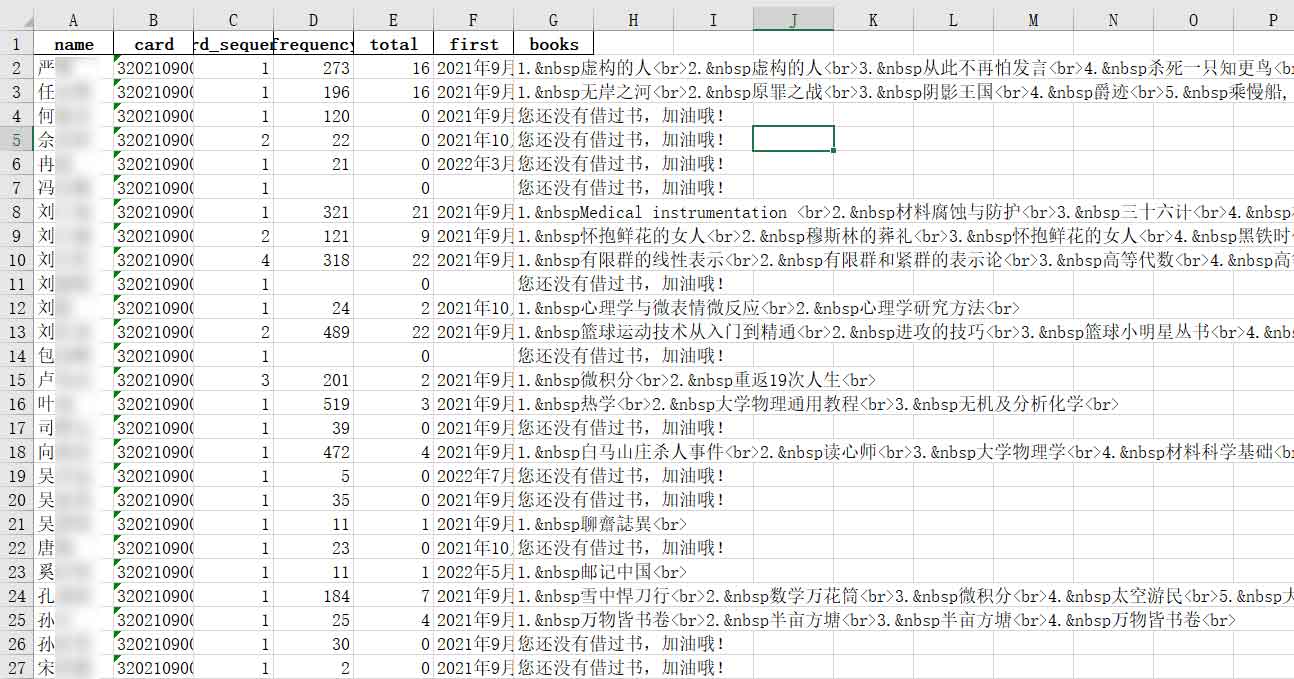
这里不再详细介绍爬取过程,总之需要做必要的尝试。
结语
分析爬取的数据发现本次泄露的师生校园卡数据范围很大,除了极少数没有开通图书馆借阅服务的校园卡号没有泄露,其他几乎全部一览无余(包括老师、博士、硕士、本科生和临时人员的校园卡号),并且系统开放至去年六月所有时间段均可以查询(2023年6月及以后注册的校园卡似乎没有同步到数据库不能查询,在此之前的时间段均可以查到)。通过查询信息还了解到,图书借阅记录涵盖了从2017年7月管理系统建成后到现在的所有借阅记录。(此外经测试发现,借阅图书后新借阅的图书数据并不会在页面上展示,而是还书后才会同步)
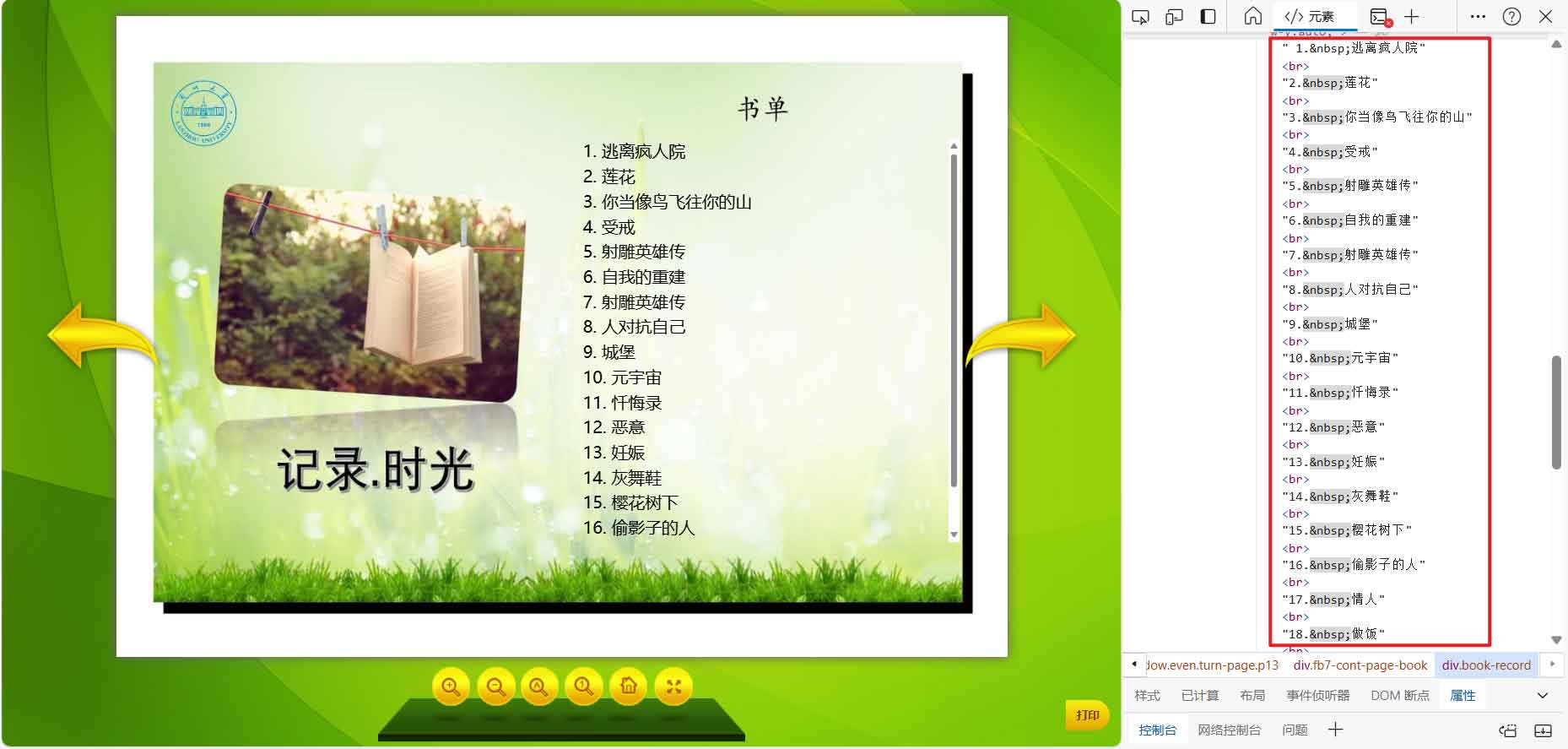
登录该服务只需校园卡号,无需密码,而且没有类似验证码的反爬机制。(连我这种菜鸟都可以爬下来就可想而知有多不安全了 ![]() )
)
最后吐槽一句,如果相关技术人员实在是想偷懒应付一下,至少把这个查询服务放在校园内网里面啊,然而也没有 ……
Leave a comment